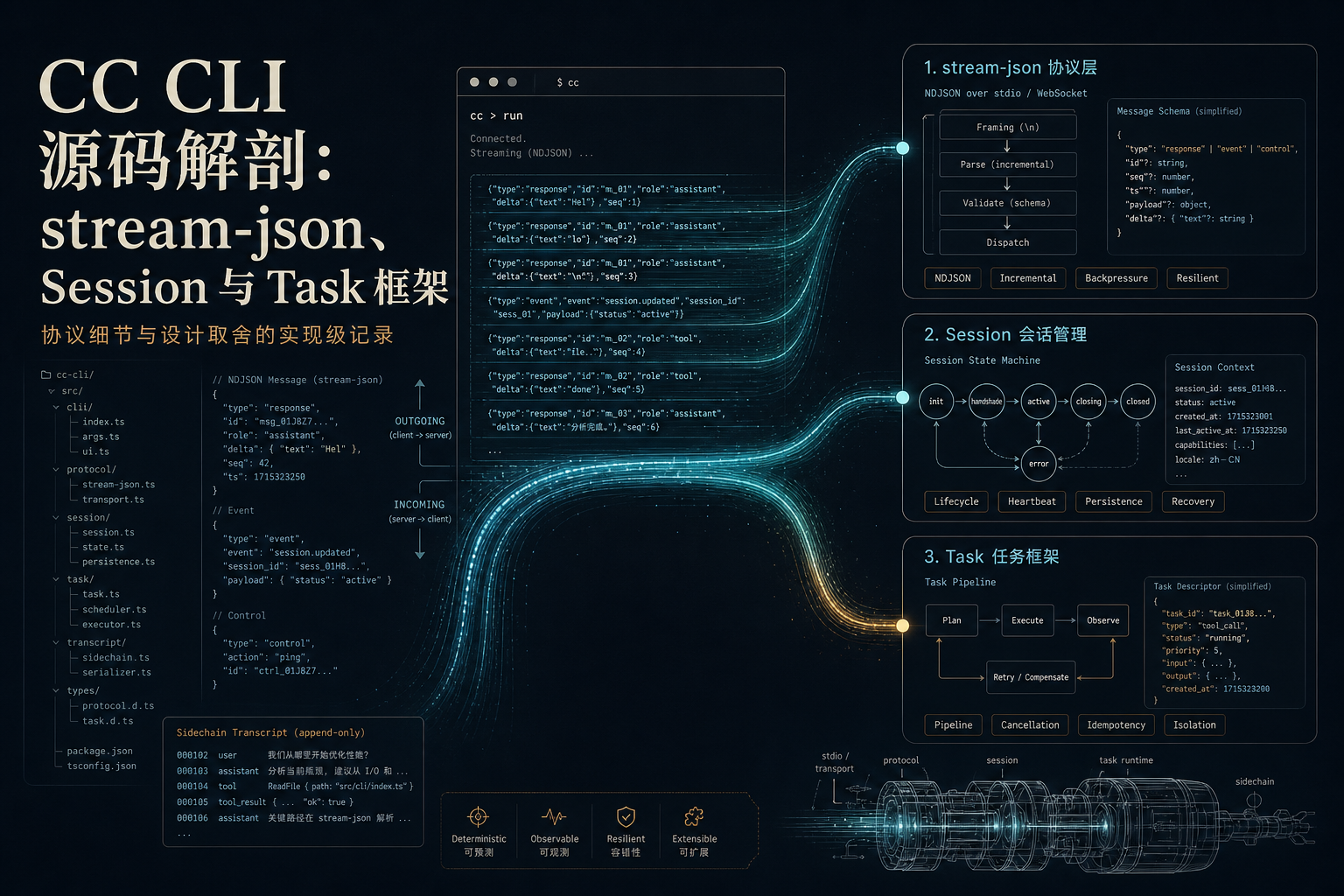
CC CLI 源码解剖:stream-json、Session 与 Task 框架
给 Vyane 写 Claude Code 的对接层(adapter,就是把一个外部程序包一层、让自己系统能调它的胶水代码)时,我撞上一堆官方文档没写的坑。文档说”加 --output-format=stream-json 就能拿到结构化输出”,但没告诉你:这条 stdout 流其实是条双向总线,CLI 会冷不丁反过来朝你要权限确认;也没告诉你 schema 文件里声明了二十多个事件类型,其中好几个在当前实现里压根不存在。
所以我干了件笨功夫的事:把 CC CLI 的源码一个文件一个文件啃了一遍。这篇是我啃完后的整理。不是 API 教程,是写给”想在 CC CLI 上面搭东西的人”的实现级笔记——你要真往上搭,这些坑我先替你踩了。
stream-json:不只是”结构化输出”
它是一条双向 NDJSON 总线
很多人——一开始我也是——以为 stream-json 就是”CLI 往 stdout 吐 JSON,每行一个事件”。这只说对了一半。
完整的图是这样:stdin 按行读 JSON,stdout 按行写 JSON。普通对话事件、控制请求、控制响应、取消请求、心跳,全挤在同一条流里复用。而且 stream-json 硬性要求和 --verbose 一起用——不加 verbose 直接报错退出。如果你传了 --sdk-url,CLI 会自作主张把进出两个方向的格式都切成 stream-json,顺手把 verbose 和 print 也打开。
换句话说,这不是一条”只读的事件流”,这是一个双向协议。你以为你在听它说话,其实它随时会反问你。
stdout 上跑着什么
把 print.ts、QueryEngine.ts、StructuredIO.ts 这几个文件翻完,我把当前真正会写到 stdout 的事件类型整理成一份完整清单:
核心对话事件:assistant(归一化后的助手消息)、user(归一化后的用户消息)、result(整轮执行的最终结果)、stream_event(token 级 partial 事件,需要显式开启)。
系统事件:十多个 system.* 子类型,包括 status(权限模式/compacting 变化)、compact_boundary(压缩边界和元数据)、api_retry(重试通知)、hook_started/progress/response(hook 生命周期)、task_started/progress/notification(任务生命周期)、session_state_changed(会话状态变化,不是默认开启的)。
控制协议消息:control_request(CLI 反向给宿主发请求)、control_response(宿主的响应)、control_cancel_request(CLI 取消未完成的请求)、keep_alive(心跳帧)。
最让我意外的是 control_request。CLI 会主动往 stdout 发权限请求,然后干等着宿主(也就是调它的那个程序)从 stdin 回一句同意还是拒绝。这不是什么犄角旮旯的边缘情况——每次工具调用都可能触发。要是你的 adapter 只盯着 result 看,你会发现 CLI 卡在那儿一直等你回话,而你压根不知道它在等什么。一个挂死的进程,根因就在这。
stdin 接受的控制指令
stdin 这头也不只是”发用户消息”那么简单。print.ts 的主循环实际处理二十多种 control_request 子类型:从 initialize(初始化整个 SDK 会话)到 interrupt(打断当前这一轮),从 set_permission_mode(切权限模式)到 mcp_set_servers(不重启、直接热更新 MCP 配置),甚至还有 remote_control(拉起远程控制桥)和 side_question(旁路提问,不打断主线插一句)。
这些指令一看就是给 IDE 和后台守护进程(daemon)这类宿主用的,不是留给终端用户手敲的。但公开文档里几乎只字未提。你不读源码,根本不知道这些钩子存在。
schema 和实现的偏差
这块是最坑的。controlSchemas.ts 里的联合类型(union,就是”这个字段可能是 A 也可能是 B”的那种声明)把 can_use_tool、hook_callback、elicitation 也塞进了 stdin 控制请求的定义里,但 print.ts 的 stdin 分发逻辑根本不处理这几个。它们其实是反着来的——是 CLI 往 stdout 发给宿主的请求。你要照着 schema 文件写解析器(parser),方向直接搞反。
这种对不上的地方还有好几处。coreSchemas.ts 声明了 system.init 和 system.local_command_output,但当前 stream-json 这条路径里找不到它们到底在哪发出来。task_progress 事件在实现里会多带一个 workflow_progress 字段,schema 里却没声明。
一句话教训:对接这套协议,真正算数的(source of truth,也就是”以谁为准”)不是 schema 文件,是 print.ts 里实际跑的那套控制流。文件声明的是它”打算支持什么”,代码跑的才是它”现在真支持什么”——以后者为准。
缓冲和时序:result 不等于”完事了”
还有个容易栽的坑是 result 事件的时序。直觉上,收到 result 就等于”这轮聊完了”。但只要有后台任务还在跑,result 就会被压着不发,等后台任务全排干(drain,就是排队的活儿全处理完)才放出来;prompt_suggestion 跟着往后顺延;session_state_changed(idle) 要等收尾的 finally 块冲刷(flush)完才补发——而且这个事件默认还不开,得手动打开 CLAUDE_CODE_EMIT_SESSION_STATE_EVENTS。
稳妥的做法是:把 result 理解成”主线这轮已经出结果了”,后台任务的死活另看 task_* 那一系列事件。要是环境你能控制,干脆把 session state 事件打开,拿 idle 当”这一轮真正收工了”的权威信号——别拿 result 当收工铃,它响得太早。
Session 管理:没有 SessionManager 的 Session 管理
拼出来的架构
CC CLI 的会话(session)管理没有一个统管全局的 SessionManager 类。它是好几块零件拼出来的:
- 运行时状态在
bootstrap/state.ts。持有sessionId、parentSessionId、sessionProjectDir。 - 主 transcript 持久化在
sessionStorage.ts。负责 JSONL 落盘、metadata 缓存与重写、compact 后恢复、subagent sidechain transcript。 - resume 装载分两步:
loadConversationForResume()读 transcript 并恢复附加状态,processResumedConversation()接管当前进程状态。 - compact 在
services/compact/。自动 compact 先试 Session Memory compact,不行再走传统摘要 compact。 - Session Memory 在
services/SessionMemory/。这是个 post-sampling hook,后台起 forked agent 维护当前 session 的summary.md。
一句话拎清这套架构的核心原则:主对话记录(transcript)是只追加不修改的 JSONL 文件(append-only,就是只往末尾加行、从不回头改旧行);元数据靠追加新条目来更新,不在原地改;压缩(compact)也不动旧记录,只写一条分界线和一份摘要,等恢复的时候再来裁剪。
延迟落盘
有个细节挺巧:启动时就把 sessionId 生成好了,但记录文件并不马上落地。sessionFile 一开始是 null,所有条目先在内存里攒着。直到第一条 user 或 assistant 消息进来,materializeSessionFile() 才真正把文件建出来。这样一来,一个只 initialize 了、还没开口说过一句话的 session,不会在磁盘上留下空垃圾文件。
元数据的持久化也守着同一条”只追加”的规矩。会话标题、标签、agent 名、模式——这些全是”追加一条新记录”,没有谁去原地改。reAppendSessionMetadata() 会在压缩之后和退出时,把最新的元数据再压一份到文件末尾,保证只扫文件尾巴(tail scan)就能读到最新值,不用从头翻。
文件布局
~/.claude/projects/<sanitized-cwd>/
<sessionId>.jsonl # 主 transcript
<sessionId>/
subagents/
agent-<agentId>.jsonl # subagent sidechain
agent-<agentId>.meta.json # subagent 元数据
remote-agents/
remote-agent-<taskId>.meta.json # 远程 agent
session-memory/
summary.md # Session Memory 摘要每条记录文件的权限是 0o600,目录是 0o700(也就是只有文件主人能读写,别人连看都看不了)。摆明了不想让其他进程随便读写这些东西。
resume 不是回放
--continue 和 --resume 这俩的行为差别得拎清楚。--continue 是抓当前项目目录下最近一个能接着干的 session,会跳过还活着的后台 session。--resume 更灵活,支持指定 UUID、自定义标题、用选择器(picker)搜、给 .jsonl 路径、甚至给一个 URL。
但不管你走哪条路,resume 都不会在 stdout 上把历史事件流重放一遍。resumeSessionAt 干的只是把已经加载进来的消息截到你指定的那个位置,不会额外回放。print 模式里我连 processSessionStartHooks('resume') 的调用都没找着。
这事的含义很硬:如果 Vyane daemon 想做”断线重连、把之前的历史补回来”,别指望挂上 stdout 流就能把之前的事件捞回来——它不会重播。要么你自己把对话记录缓存下来,要么另外去读 session 的持久化文件。这是绕不过去的,得在 Vyane 这边自己解决,CC 不替你兜底。
Compact 怎么保持 session 可 resume
压缩(compact)不是简单粗暴的”把历史总结一下、旧消息删掉完事”。它更像是一次精心设计的视图切换——旧数据还在,只是换个角度看。
自动压缩的执行顺序是:先试轻量的 Session Memory 压缩(直接拿 summary.md 当摘要,不花钱调模型),不行再退回传统压缩(调模型做总结)。连着失败 3 次,触发熔断(circuit breaker,就是连续出错就先停手别硬试,免得越捅越糟)。
传统压缩会把图片和文档换成文本占位标记,把技能发现(skill discovery)的附件剥掉,但会把最近读过的文件内容重建回来(最多 5 个,总预算 50k token)、还有计划文件、已调用的技能状态、异步任务状态等等。压缩分界线里还会存一份 preCompactDiscoveredTools,免得把已经发现的延迟加载工具(deferred tool)给弄丢了。
Session Memory 压缩更轻:直接读 summary.md 当摘要,不调模型。它带一个保留窗口(默认至少留 10000 token 或 5 条文本块消息),而且不会把”工具调用 / 工具结果”这一对、或者同一条消息上的思考块(thinking block)从中间劈开。要是压完 token 还是超线,它就老老实实返回 null,让上层退回去走传统压缩——不硬撑,知道自己搞不定就交回去。
resume 时的恢复全围着压缩分界线(compact boundary)转。大文件会先扫这条分界线,只把它之后的主体内容加载进来,分界线之前的部分只做一次轻量的元数据扫描。被保留下来的那段有专门的重新挂链逻辑:重挂 parentUuid(父消息指针)、把用量计数清零(不然 resume 完立马又误触发自动压缩),再把不在保留名单里的旧消息删掉。
结论:压缩过的 session 照样能 resume,但你恢复出来的是”分界线之后那份有效视图”,不是从头到尾的完整历史。
7 种 Task 和状态机
Task 类型体系
CC CLI 内部有 7 种任务类型:
| 类型 | ID 前缀 | 用途 |
|---|---|---|
local_bash | b | 后台 shell 命令 |
local_agent | a | 本地 subagent |
remote_agent | r | 远程 agent trigger |
in_process_teammate | t | 进程内 teammate (Agent Teams) |
local_workflow | w | 本地 workflow |
monitor_mcp | m | MCP server 监控 |
dream | d | autoDream 记忆整合 |
任务 ID 的格式是 {类型前缀}{8 位随机字符},用 36 个字符的字母表,36 的 8 次方差不多 2.8 万亿种组合,撞 ID 基本不用担心。看前缀就能一眼认出这是什么任务,挺省事。
状态机
pending -> running -> completed
-> failed
-> killed五个状态,三个是终点(终态)。到了终点的任务就回不来了——没有重启机制,想再跑只能新建一个。isTerminalTaskStatus() 统一判断一个任务是不是已经走到头了。
杀任务(kill)的流程,拿 dream 任务举例:先看它是不是还在跑(已经到终点就跳过),发出中止(abort)信号,把锁状态里的 priorMtime(之前的修改时间)存下来,再把状态置成终态。杀完之后会把锁回滚,好让下一个 session 还能重新来一遍。
输出管理
每个任务有自己单独的输出文件,outputOffset 记着上回读到哪了,所以能增量读、不用每次从头读。SDK 这边的消费方靠 task_notification 事件知道任务完事了。notified 这个标记是用来防止同一件事重复通知的。
Forked Agent:共享 cache,隔离状态
核心机制
分叉 agent(Forked Agent)是 CC CLI 在后台跑隔离子任务的机制。会话记忆提取、autoDream 记忆整合、技能执行、提示建议生成、回合结束后的总结,这些活儿都靠它。“分叉”就是从主进程身上岔出一个分身去干私活,干完不影响主线。
设计原则就八个字:共享缓存,隔离可变状态。
具体怎么做的:分叉 agent 会把父进程的完整消息历史背上,当作 forkContextMessages,再加上自己这趟的任务指令当 promptMessages。因为发给 API 的请求前缀(系统提示 + 工具 + 模型 + 父进程消息)跟父进程一模一样,Anthropic API 的提示缓存(prompt cache,命中了就不重复算钱)会直接命中——几乎不花额外 token,就把完整上下文拿到手了。
而所有”会被改的状态”(可变状态)默认全隔离。createSubagentContext() 会克隆一份父进程的 readFileState,新建一个子级的中止控制器(父进程一中止,会顺着传下来),把 setAppState 换成空操作(no-op,就是个啥也不干的占位),把工具决策重置成 undefined。子 agent 碰不了父进程的界面,也左右不了父进程的权限决策。分身归分身,动不了本体。
Sidechain 录制
每个分叉 agent 有自己独立的 agentId(格式是 agent-{forkLabel}-{uuid}),对话录到一条单独的侧链(sidechain)文件里,不会去脏污主记录那条 parentUuid 链。多个分叉 agent 可以一起并行跑,各录各的,互不踩脚。
这个侧链设计我挺欣赏。主记录是一条干干净净的对话链,所有后台杂活都甩到侧链里去记,恢复的时候各走各的道。/resume 命令直接把侧链滤掉,所以用户根本看不到这些后台录制——它们是留给 agent 自己 resume 时用的,不是给人看的。主线清爽,杂事归档,这思路值得抄。
三种使用模式
按隔离的松紧程度,分叉 agent 有三种典型用法:
- 完全隔离:会话记忆、autoDream 这类后台任务,子 agent 动不了父进程的任何状态。
- 自定义选项:Agent 工具起的异步 agent,自己指定 agentId、初始消息等等。
- 交互式:共享一部分状态(setAppState、中止控制器),用在需要和父进程配合干活的场景。
autoDream:三层 Gate 策略的记忆整合
触发机制
autoDream 是后台的记忆整合机制。每轮对话(turn)一结束就检查一次,按开销从便宜到贵,依次过三道闸(gate):
第一道闸(一次 stat 调用):离上次整合是不是过了 24 小时。绝大多数回合走到这就被拦下了,开销不到 0.1 毫秒,基本等于白菜价。
第二道闸(一次目录扫描):把当前 session 排除掉,看最近是不是有 5 个以上的 session 被改过。带 10 分钟的节流(throttle,就是这段时间内别反复触发)。
第三道闸(分布式锁):靠文件修改时间(mtime)加进程号(PID)做的一把轻量锁。抢到锁,才真正启动 dream。
这套设计的妙处:绝大多数回合花一次 stat 调用就被挡回去了,只有极少数能一路走到抢锁那步。先做最便宜的判断,能挡就挡,别动不动就上重活儿。
分布式锁
锁文件 {memoryRoot}/.consolidate-lock 的数据模型设计得很巧:文件的修改时间(mtime)直接就当”上次整合时间”用,文件内容存的是当前持锁进程的 PID(进程号)。抢锁时顺手查一下这个 PID 还活着没;要是那个进程崩了(crash),下一个进程一看是个死 PID,就能名正言顺接管。一把锁顺带把”上次干到哪、现在归谁”两件事都记了,不另开文件。
回滚的情况也想到了:要是之前有 mtime(说明以前成功整合过),就把时间戳重置回那个值(相当于”时光倒流”,假装这次没发生);要是 mtime 是 0(压根没成功过),那就直接把锁删了。
四阶段整合
dream agent 的提示词(prompt)分四个阶段,我用大白话过一遍:
- 定位(Orient)——先
ls一下记忆目录、读 MEMORY.md 摸清当前索引、把已有的主题文件翻一遍,免得回头重复造。 - 搜集(Gather)——按优先级找新信息:每日日志最优先,其次是过时的旧记忆,最后才轮到去对话记录里 grep。关键策略是”别把对话记录从头翻到尾,只在有线索时才去 grep”——大海捞针前先问问针大概在哪。
- 整合(Consolidate)——把新信息并进已有的主题文件(而不是动不动新建文件),把”昨天""上周”这种相对日期换成绝对日期,再把已经被推翻的旧事实删掉。
- 修剪与编索引(Prune & Index)——更新 MEMORY.md 索引,每条不超过 150 字符,总量压在 25KB 以内。
dream agent 的工具权限被卡得很死:只能用只读的 bash 命令(ls、cat、grep 这些)和对记忆目录内文件的 Edit/Write。不能发网络请求,也不能碰项目文件。一个整理记忆的活儿,权限就只给到记忆目录这一亩三分地——别让它有机会闯祸。
Memory 提取的互斥设计
除了 autoDream 那种跨 session 的整合,CC CLI 还有一个 extractMemories 机制做增量提取——每轮对话结束后,从当前 session 里把值得长期留着的记忆挑出来。
这俩的互斥设计值得说一下:要是主 agent 自己在这轮里已经写过记忆文件了,提取就直接跳过,不去抢着写。同时 extractMemories 内部还有个重叠保护(overlap guard):上一次提取还没干完,新请求来了就先暂存(stash)起来,等前一个完事再补跑一次收尾(trailing run)。这就保证了不会有两个提取进程同时往记忆目录里写——避免两个人同时改一个文件、最后谁也说不清改了啥。
游标(cursor)机制也很实用:lastMemoryMessageUuid 记着已经处理到哪条消息了,每次只啃新增的那部分。万一游标指的那条消息被压缩删掉了,会退回去走全量计数,不会卡死在那。
为什么这些对 Vyane 重要
啃完这轮源码,我对 Vyane 的 CC 对接层(adapter)设计攒下了几条明确结论,在这儿一并交底。
对接协议别只盯着 schema 看。 controlSchemas.ts 和 coreSchemas.ts 只能当参考,不是”以谁为准”的那个准。真正得跟的是 print.ts 的 stdin 分发逻辑、StructuredIO 的缓冲和去重行为、QueryEngine 怎么翻译事件。解析器(parser)必须能容忍没见过的字段和没见过的子类型,不能照着严格 schema 死磕——它声明的和它实际跑的对不上,按声明写必崩。
stdout 是条双向复用的总线。 Vyane 的 adapter 必须把所有消息类型都接住,包括 CLI 反向发过来的 control_request(权限请求、hook 回调、MCP 消息)。不能只盯着 assistant 和 result 那两样,不然 CLI 在那头等你回话,你这头还以为它没动静。
resume 不是一个”重播历史”的协议。 Vyane 别指望 --resume 能把历史补回来,得自己缓存对话记录或者去读 session 文件。这直接决定了 Vyane 的 session 持久化策略——CC CLI 不替你兜底,这活儿得自己扛。
分叉 agent 的隔离模型,可以直接当 Worker Manager 的模板。 “共享缓存、隔离可变状态”的原则、侧链录制不脏主链的设计、中止信号往下传的机制——这些都能原样映射到 Vyane 的 worker 体系上。区别只在于 CC 是进程内隔离、Vyane 是进程级隔离,但思路是通的,照搬就行。
三道闸是个值得抄的自动触发范式。 最便宜的检查先做,最贵的留到最后。Vyane 的自动任务调度可以直接套:时间闸(离上次跑过多久)、条件闸(有没有待处理的活儿)、锁闸(是不是已经有别的实例在跑了)。
任务状态机够简单、够用。 五态三终点,没重启、只能新建。Vyane 要在这基础上补一个 interrupted(被打断)态来支持 resume,再加个心跳超时检测,但底子可以直接复用,不用重造。
还有一点得说清楚:源码里那些具体数字——压缩的 50k token 文件预算、dream 的 24 小时和 5 个 session 阈值、提取的 5 轮上限(maxTurns)、锁文件 1 小时算”过期”(stale)——都不是拍脑袋随便定的,是 Anthropic 自己在生产环境里调出来的。Vyane 的初始配置完全可以从这些数字起步,再按自己的场景慢慢调。别浪费现成的经验值。
